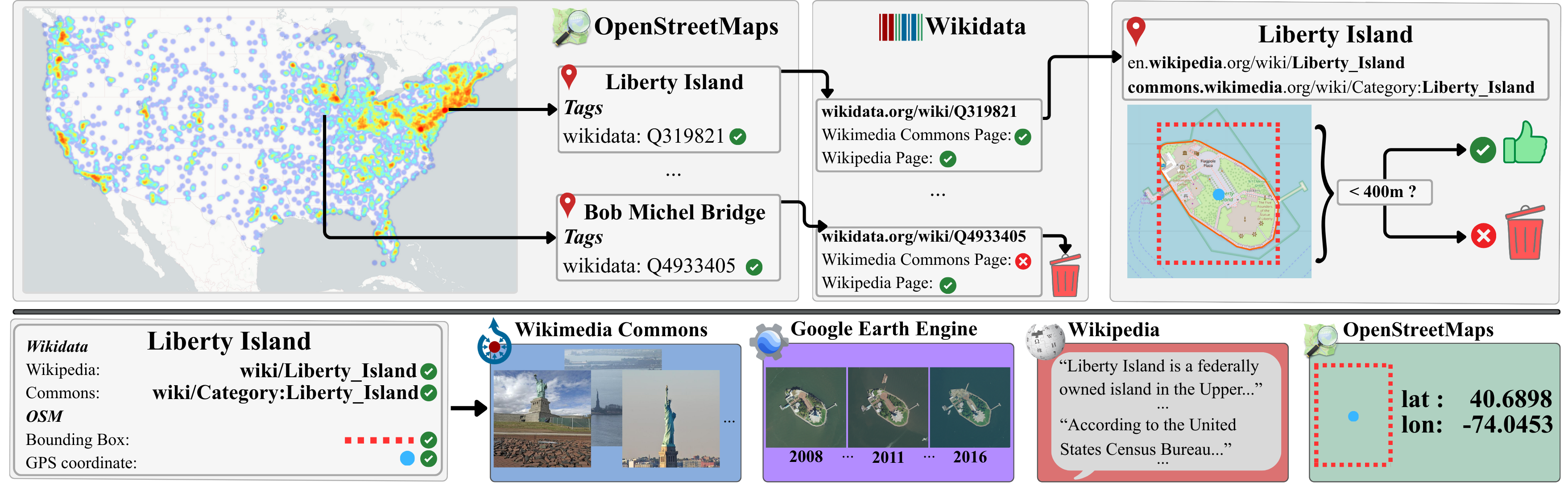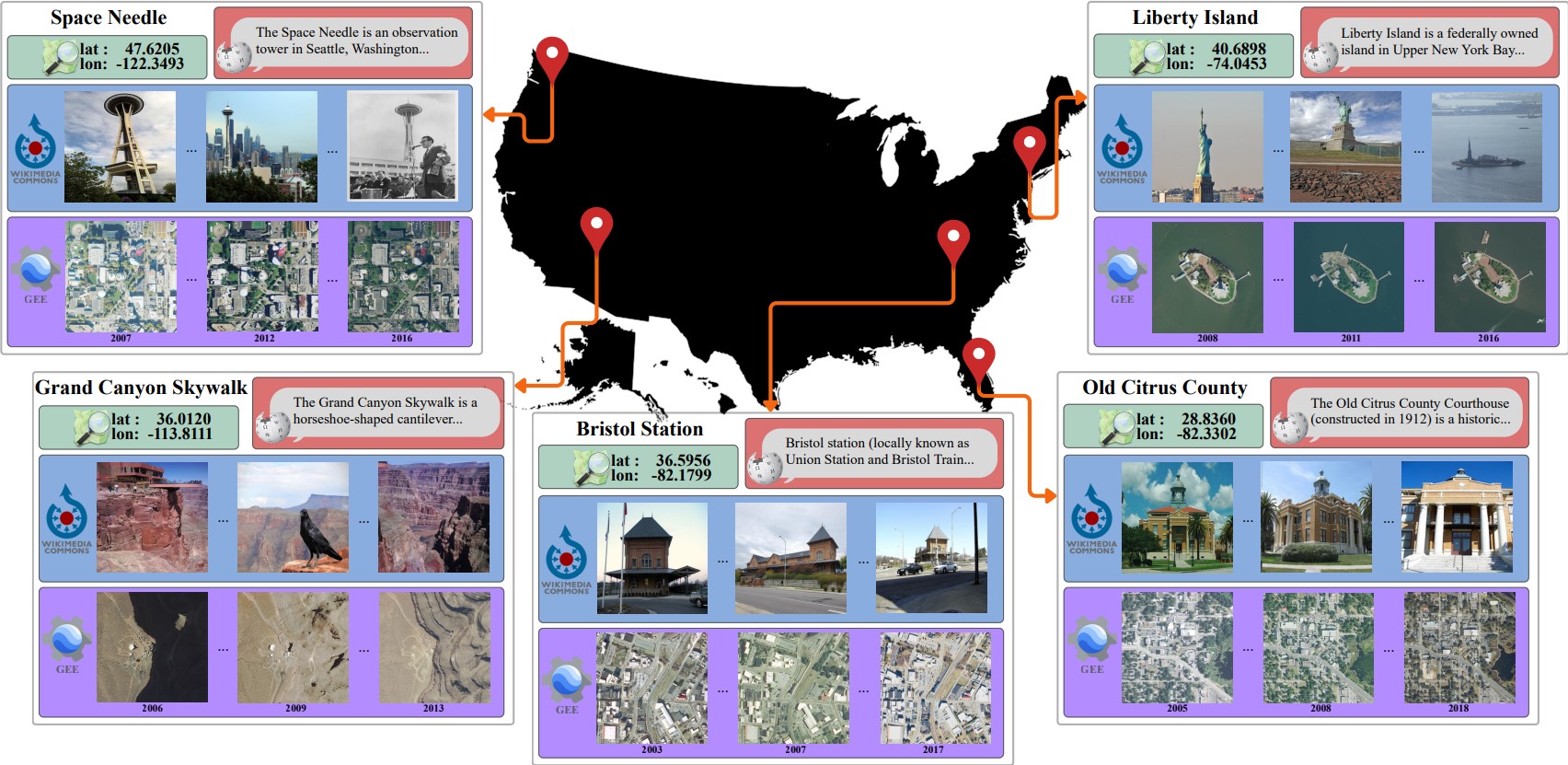
MMLandmarks: We present four distinct data modalities: ground-view images, aerial-view images, GPS coordinates, and textual descriptions, collected from 18,557 unique landmarks in the United States. Data sources are included alongside each modality.
🎉 Accepted at CVPR 2026 🎉
TL;DR - What is MMLandmarks ?
MMLandmarks is a large-scale multimodal benchmark for geo-spatial understanding, uniquely combining four complementary modalities—ground-level imagery, aerial/satellite imagery, GPS coordinates, and Wikipedia text—for the same set of landmarks. Unlike prior datasets that focus on a single view or modality, MMLandmarks enables cross-view and cross-modal retrieval at the instance level. All 18,557 landmarks are geographically distributed across the United States, sourced from OpenStreetMap and Wikimedia Commons under open licenses, making the dataset fully reproducible and suitable for academic research.
| Task | Dataset | Year | Train(G/S) | Index(G/S) | Instances | Scale (Cities) | Modalities | Open-access | License |
|---|---|---|---|---|---|---|---|---|---|
| Geo localization |
IM2GPS | 2008 | 6.4M/- | - | - | Global | G,C | ✗ | N/A |
| YFCC100M | 2016 | 100M/- | - | - | Global | G,C | ✓ | Flickr TC | |
| PlaNet | 2016 | 126M/- | - | - | Global | G,C | ✗ | N/A | |
| MP16 | 2017 | 4.7M/- | - | - | Global | G,C | ✓ | Flickr TC | |
| OSV-5M | 2017 | 5.1M/- | - | - | Global | G,C | ✓ | CC-BY-SA | |
| Cross-View Retrieval |
CVUSA | 2015 | 35k/35k | 8.8k/8.8k | - | USA(1) | G,S | ✓ | Flickr TC |
| Vo. | 2016 | 450k/450k | 70k/70k | - | USA(11) | G,S | ✓ | N/A | |
| CVACT | 2019 | 44k/44k | 92k/92k | - | Australia(1) | G,S | ✓ | N/A | |
| Uni-1652 | 2020 | 11.6k/701 | 5.5k/1652 | 1652 | 72 Universities | G,S,D | ✓ | N/A | |
| VIGOR | 2021 | 51k/44k | 53k/46k | - | USA(4) | G,S | ✓ | N/A | |
| CV-Cities | 2024 | 162k/162k | 61k/61k | - | Global(16) | G,S | ✓ | N/A | |
| CVGlobal | 2024 | 134k/134k | - | - | Global(7) | G,S | ✓ | N/A | |
| Landmark Retrieval |
R-Oxford | 2018 | - | 5k + 1M/- | 11 | Oxford | G | ✓ | Flickr TC/CC |
| R-Paris | 2018 | - | 6k + 1M/- | 11 | Paris | G | ✓ | Flickr TC/CC | |
| GLDv1 | 2018 | 1.2M/- | 1.1M/- | 30k | Global | G | ✗ | Multiple | |
| GLDv2 | 2020 | 4.1M/- | 764k/- | 200k | Global | G | ✓ | CC/Public-domain | |
| MMLandmarks | 2026 | 329k/197k | 714k/100k | 18,557 | USA | G,S,T,C | ✓ | CC/Public-domain |




@InProceedings{Kristoffersen_2026_MMLandmarks,
author = {Oskar Kristoffersen and Alba Reinders and Morten R. Hannemose and Anders B. Dahl and Dim P. Papadopoulos},
title = {MMLandmarks: a Cross-View Instance-Level Benchmark for Geo-Spatial Understanding},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2026},
}